紅米手機如何啟動USB偵錯模式
小米手機如何啟動USB偵錯模式
紅米手機如何啟動USB偵錯模式
● 在 手機 桌面,按下【齒輪圖示】
● 在 設定 頁面 ,按下【關於手機】
● 在 關於手機 頁面 ,按下【MIUI版本號碼】
● 連續點按5下【MIUI版本號碼】,就會顯示【已開啟開發人員模式】。
● 返回【設定 頁面】。
● 在 設定 頁面 ,按下【更多設定】
● 在 更多設定 頁面 ,按下【開發者選項】
● 在 開發者選項 頁面 ,按下【USB 偵錯】。
● 完成啟動USB偵錯模式。
小米手機如何啟動USB偵錯模式
紅米手機如何啟動USB偵錯模式
● 在 手機 桌面,按下【齒輪圖示】
● 在 設定 頁面 ,按下【關於手機】
● 在 關於手機 頁面 ,按下【MIUI版本號碼】
● 連續點按5下【MIUI版本號碼】,就會顯示【已開啟開發人員模式】。
● 返回【設定 頁面】。
● 在 設定 頁面 ,按下【更多設定】
● 在 更多設定 頁面 ,按下【開發者選項】
● 在 開發者選項 頁面 ,按下【USB 偵錯】。
● 完成啟動USB偵錯模式。
+86 4008588888
1. 按1 普通話
2. 按2 個人業務
3. 按0 人工服務
先留大陸手機號碼、E-mail 等候電話通知
廈門銀行,在微信號上面找更新台胞證的作業,先連絡上一般客服後會再通知專員跟你聯絡進行更新資料的作業。
整個流程大概一週,4天等待,2天給你準備資料跟驗證資料,1天視訊搞好。
小米手機 檔案管理- 按資料夾圖片
小米相冊 (sdcar)/DCIM/Camera/
內部儲存空間(sdcar)/Download/WeChat/
(sdcar)/Pictures/WeChat/
他會在微信上開一群組並請你準備好以下資料
1.更新后的台胞證原件;
2.一份新臺胞證影印件(正反面影印在一張A4紙上);
3.一份臺灣身份證影印件(正反面影印在一張A4紙上);
並在影印件上用黑筆寫上(一定要手寫)“此复印件仅用于厦门银行办理证件更新使用”


厦门银行台湾客户证件过期远程核实需要提供相关材料,材料清单及填写要求具体如下:
1.填写《个人银行账户使用法律责任告知书》,抄录“我已阅读并承诺依法依规使用本人账户”,暂不签名;稍后给您发一个公众号推文,选择其中2个视频观看后,在是否已观看2个反诈宣传视频“是”打勾
2.填写《涉税信息》表格,个人税收居民身份声明文件全部信息都要填写,最下面本人签署处签名(注意不要签在审核经办处,税收居民国写中国台湾,居民国纳税人识别号写台湾的身份证号),暂不签名
3.将最新的台胞证、台湾身份证正反面复印在同一张纸上,并在复印件空白处书写:“此复印件仅用于厦门银行办理证件更新使用。”暂不签名
另:远程视频核实时,需有另一个人协助拍摄,请准备好以上材料(全部打印出来)和黑色签字笔,我们需要视频时核对签名字迹,感谢您的配合。 要拍的臉部正面和錄音,旁邊的行員會照相。
最後會問你台灣手機號碼、行業別、收入(換算成人民幣)、台灣現居地址、郵遞區碼
借记卡期限到期 ,如果受疫情影响辺境封鎖,無法去网点辦理更新,请問是否有其他方式。
您有开通手机银行吗?预计6月中旬会在手机银行实现线上换卡申请、寄送、自助激活等功能,可支持线上办理
IC卡到期后如没有及时更换的,不影响资金入账、在线转账,微信、支付宝、银联、云闪付绑卡、银行卡代扣,但实体卡POS消费及ATM交易会受影响。
通過手機銀行取消短信通知,登錄手機銀行後,點擊“設置,"安全中心" 下方" 銀行卡" 往下拉 "銀行卡管理" "更多功能" ,"招行短信服務" ," 修改 " 賬務變動通知 知擊 短信通知(3元/月) 取消,點擊通知Email 免費,"通知內容是否包含餘額 改是"
您好,若是通過手機銀行取消短信通知,登錄手機銀行後,點擊“我的”-“銀行卡”,選擇銀行卡,點擊“其他”-“招行短信服務”,根據提示操作關閉.
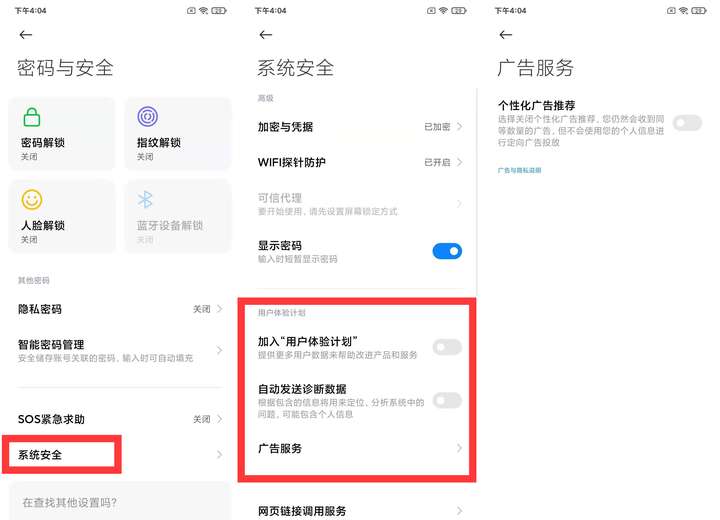
Read more...一、關閉系統廣告
點擊設置-密碼與安全-系統安全。將以下三個按鈕全部關閉
加入用戶體驗計劃
自動發送診斷報告
廣告服務-個性化廣告推薦
點擊設置-應用設置-系統應用設置,按照下面提示一個一個全部關閉廣告推送提醒
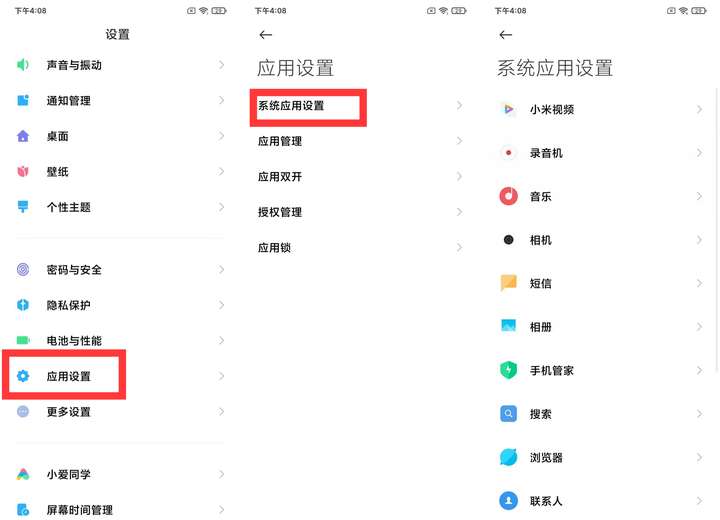
1、小米視頻:
消息設置,關閉“未讀消息提醒”,
體驗計劃-消息通知管理-關閉“允許通知”按鈕。
2、音樂:
通知設置,關閉“通知提醒”。
當然,如果你平時不用這個軟件聽歌,可以關閉“個性化內容推薦”/關閉“在線內容服務”這樣就變成了純粹的本地播放器了。
3、短信
高級設置-關閉“允許WAP推送”
4、手機管家
關閉最下方的“推薦內容”和“僅在WLAN下推薦”
手機管理裡面還有一個垃圾清理,同樣也要關閉“推薦內容”和“僅在WLAN下推薦”
5、搜索
消息通知管理-關閉“允許通知”
6、瀏覽器
消息通知管理-關閉“接收通知欄消息”
高級設置-關閉“宮格位推送”和“個性化推薦”
如果你不喜歡常規的信息流主頁,也可以在這個頁面開啟簡潔版主頁。(可選)

7、聯繫人
關閉“聯繫人顯示黃頁入口”
這個功能主要是能查詢各種黃頁電話信息,如果不喜歡直接關閉更加簡潔。
8、日曆
用戶體驗計劃,關閉“內容推廣”
9、應用商店
通知設置-關閉“推送消息”和“新手幫助”,點贊評論消息其實也沒用可以關閉
推薦-關閉“個性化推薦”和“相關推薦”
在手機桌面上,點擊對應的app進入,按照下方步驟操作
1、天氣
右下角三個點-設置-用戶體驗計劃,關閉“今日資訊卡片”和“天氣服務推薦”。
2、日曆
右上角三個點-設置-用戶體驗計劃,關閉“內容推廣”
3、安全中心
中間有一個應用管理,右上角三個點-設置-關閉“應用升級提醒”和“資源推薦”。
4、下載管理
右上角三個點-設置-信息流設置,全部關閉“資源推薦”“熱榜推薦”“僅在WLAN下加載”。
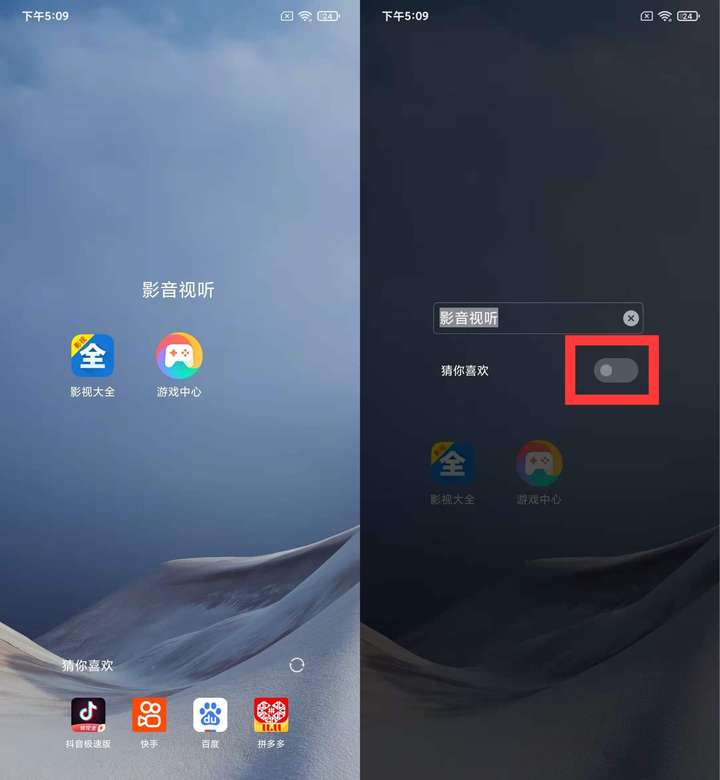
5、桌面的應用夾(幾個應用放在一個文件夾裡面)
打開應用夾,輕點一下應用夾名稱,即可關閉“猜你喜歡”。
我這個新手機升級MIUI12默認是關閉的,如果你的是開啟的可以手動關閉
6、小米自帶搜狗輸入法
設置-更多設置-語言與輸入法,輸入法管理,由於系統自帶多個輸入法包括百度和訊飛,你可以卸掉不需要的輸入法。
如果你留下的是搜狗輸入法,要在輸入法管理,設置-輸入習慣-關閉“節日活動提醒”
其他輸入法貌似沒有廣告。
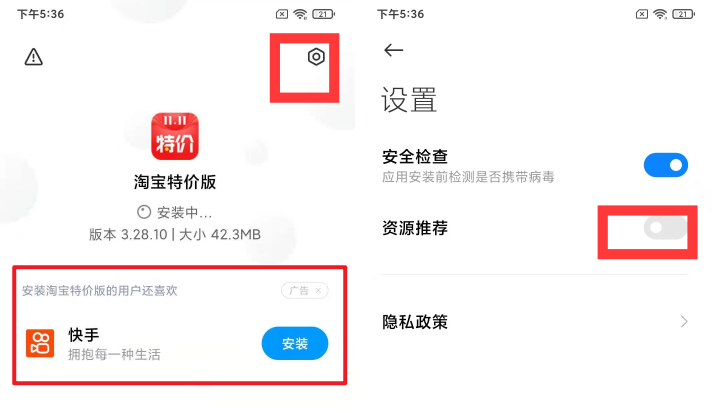
7、非官方渠道手動安裝應用
建議原則上大家都通過小米官方的應用商店下載,安全放心一點。
當然有時候會手動從別的渠道下載一些手機軟件,安裝的時候就會出現廣告推薦,可以關閉。
在安裝界面,點擊右上角,設置-資源推薦,關閉即可。
8、其他軟件
至於其他小米自有應用比如小米社區,遊戲中心,以及你自己下載的其他應用比如騰訊視頻,今日頭條等等都是可以直接卸載的,或者在軟件的個人中心修改消息推廣設置。
到此,手機的廣告已經被全部關閉了。
最後:在補充一點,通知欄軟件頻繁推送的消息,有的是廣告,有時候是一些消息動態,如果想省事一點,不希望各種軟件消息一大堆,那麼可以直接關閉軟件通知欄消息推送功能,你會馬上感覺世界清淨了不少呢。
如何關閉軟件通知功能?
點擊設置-通知管理,(分為鎖屏通知,懸浮通知和應用角標小紅點提醒三種)
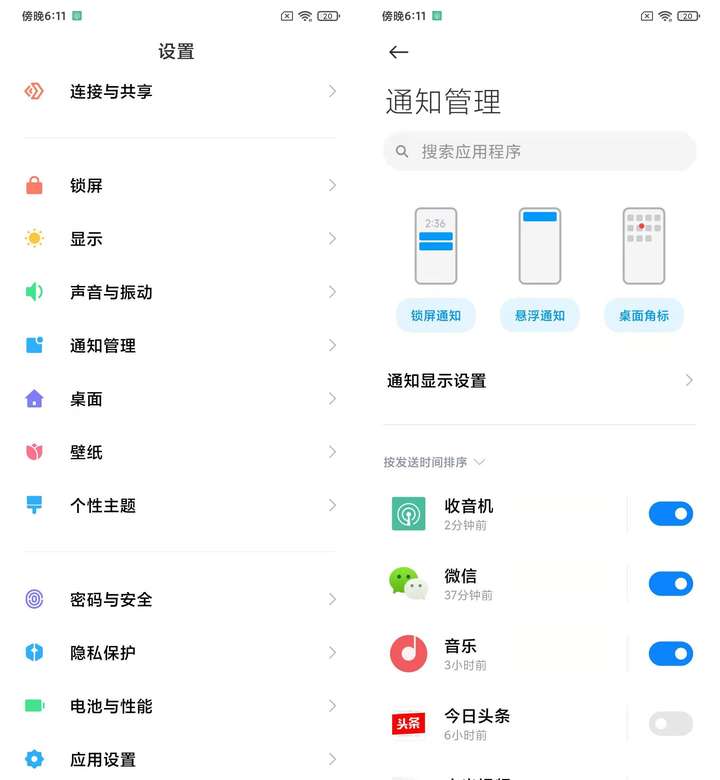
可以看到所有手機安裝的APP
點擊開關按鈕,直接關閉所有消息提醒功能。
點擊APP的名字,可以具體選擇性關閉某一類通知。
終於取得Google AdSence的使用資格了!建議與心得分享
© Blogger templates Psi by Ourblogtemplates.com 2008
Back to TOP